I am a big believer in the power of semantic layers to establish organizational trust in data, and have spent the last decade working in tools that center around data modeling. Semantic layers set out to define business logic, generally sitting between the data store and business users. Business Intelligence tools typically either house the semantic layer or sit as a naive layer on top. Historically, this either/or approach has created a clash between governance vs. self-service. At Omni, we’re taking a new, more balanced approach.
Last week at the dbt Coalesce conference, there was a lot of discussion around semantic layers and where business logic should sit. In these conversations, I am often asked:
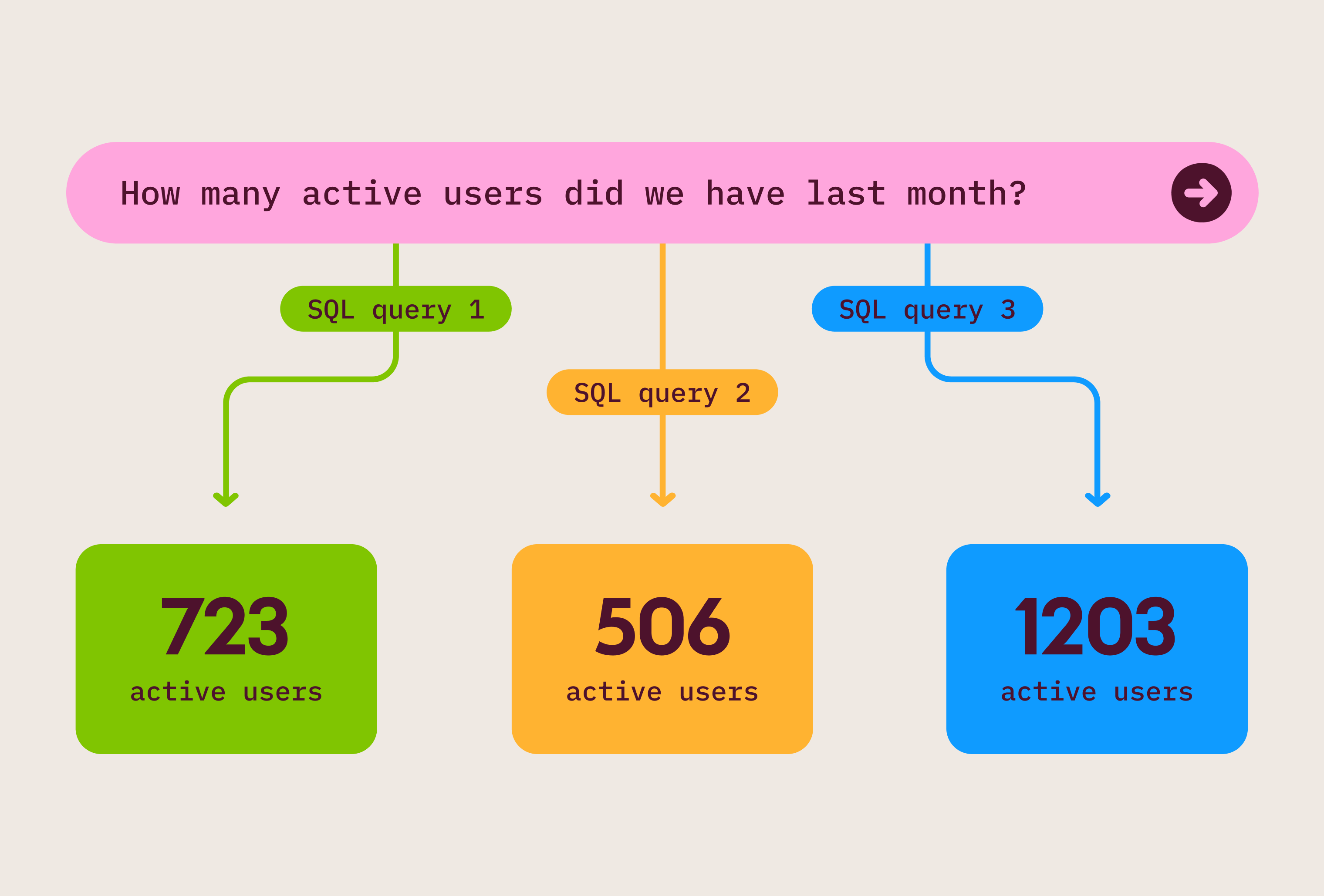
“Why do I need a BI tool with a data model/semantic layer if I’m using dbt?”
This isn’t an either/or decision; it’s best to take a hybrid approach. We use dbt and Omni together, as do many of our customers.
In this blog, I’ll walk through:
Why you should consider combining dbt and a BI tool’s semantic layer for data modeling
Guidelines for using dbt alongside Omni’s semantic layer
An example use case where using a hybrid approach provides an optimal setup
If you’re looking to learn how to use Omni’s bi-directional integration with dbt, check out Chris’ post for more details.
Differences between data modeling in dbt vs. Omni’s semantic layer #
Let’s start by understanding the strengths of modeling data in either dbt or a BI tool’s semantic layer (specifically Omni’s).
From a technical standpoint, the core difference between modeling in dbt vs. a semantic layer is when/where transformation happens:
dbt performs transformations in advance and organizes them into views/tables in the data warehouse.
Omni performs transformations at query time and uses a smaller unit of logic.
Before we move on, it’s important to call out the difference between how dbt is optimally used with BI tools that have semantic layers vs. those that don’t. Many BI tools available today do not have a modeling layer that allows for the creation of reusable logic and definitions. In this case, the only option to centralize business definitions is in the data warehouse, so much more is done in this layer (often via dbt). When I work with organizations transitioning from these predominantly SQL- or vis-based tools without a semantic layer, they often decide to deprecate many repetitive models defined in dbt to serve specific reports. Given the option, our customers prefer to break up these reusable pieces of logic in our semantic layer.
Which layer is best for a given use case depends on how people will consume the data.
When to model in dbt #
In general, dbt is great for building, testing, and pushing downstream to integrations with other tools for core sets of definitions that need to be stable and broadly available. At a fundamental level, dbt allows you to write SELECT statements to produce table definitions into the database. The smallest unit of definition is a table, and the SELECT statement includes any transformations and additional customized fields to add to the model.
This is great for establishing stable table structures. If any other applications need to access your model definitions, they now live centrally in the database. Additionally, modeling in dbt is great for performance if the transformations you’re defining get complex - these can be pre-computed and persisted in the data warehouse, awaiting use by consumers and downstream tools.
Transform in dbt if:
✅ | Other tools will depend on the definitions (e.g. for data science and machine learning applications) |
✅ | Transformations are expensive or time-consuming to compute at query time. For example, sessionization of event data, or aggregating massive data into daily roll-ups (see example below). |
✅ | The modeling capabilities of your BI/analytics tools are non-centralized, limited, and/or require lots of manual repetition |
When to model in Omni #
In contrast, Omni’s model allows definition of reusable snippets of logic to be combined at query time for last-mile interactive analysis. The unit of definition is much smaller: it can be a single aggregation (which can be grouped or filtered by any number of dimensions at query time), a join, a table, etc.
This matters because minor additions to your data model don’t need to be a big deal. For example, adding a field to a table replicated from your application database can be done right in that table - there’s no need to add a new table in a separate schema. Doing so is simple, and given the right permissions, data analysts can be meaningful contributors to your data model; data engineers needn’t be a bottleneck to minor changes.
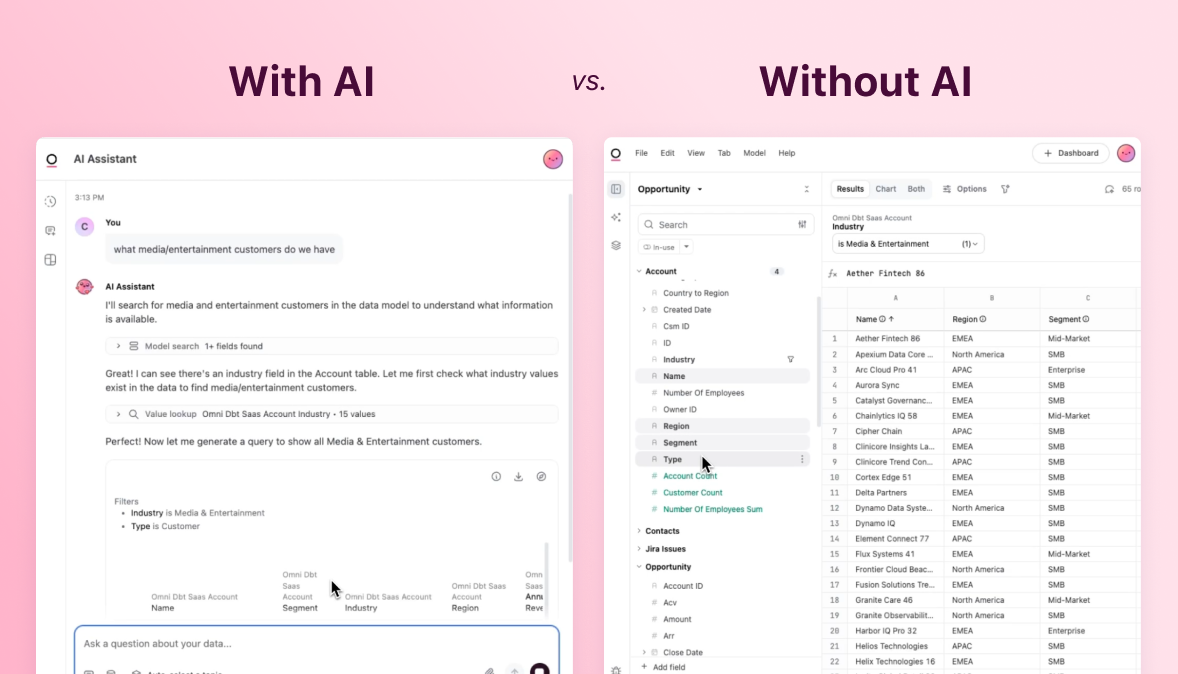
In Omni, the act of modeling in the tool is also quite different from working on dbt models. Most things can be accomplished with a click in the UI (though the code-based representation is always available), which makes for faster iteration that feels lower-stakes. Any new field or join you define can immediately be tested in the context of existing queries and dashboards. Trusted, data-savvy people can experiment more freely (again, given the appropriate permissions), and when they create something that will be useful to others, it’s easy to promote these changes back to a broader shared model.
I particularly like to model in Omni when I’m not sure what I’m looking for, and want the ability to explore and iterate before promoting metrics and definitions into Omni’s shared model, or back to dbt. Then once I move definitions into dbt, they become available in Omni without requiring manual work.
Transform in Omni if:
✅ | Users want to interact with your aggregations, including any drilling, filtering, pivoting, slicing, etc. Saving aggregation to query time retains maximum flexibility to ask follow-up questions. |
✅ | You’re not ready to commit to a metric. Omni allows for fast iteration with low commitment, making it an ideal place to test out new metrics or tables alongside existing content. This helps avoid clutter in the DWH with hundreds of single-purpose and/or abandoned models. |
✅ | You want to reduce load on data engineering resources and take advantage of more analyst-friendly modeling methods |
#
Better together: When to model in dbt and Omni #
So far, we’ve focused on when modeling is best suited for either dbt or Omni. But in real life, most use cases benefit from a hybrid approach.
Example: Analyzing massive event datasets with dbt and Omni #
A common analytical pattern I help folks set up is reporting on daily/weekly/monthly active users. When the data volumes are relatively low (e.g. transactions for a small eCommerce business), I tend to do most of this in Omni. However, when data volumes become pretty massive (e.g. if this is being defined on top of raw event stream datasets), it becomes less cheap and performant to query the entire dataset. In this case, creating a dbt model to define a daily rollup of these metrics can be pretty appealing. This works fine for putting some charts on a dashboard.
However, the issue arises when users inevitably want to filter on attributes of individual users, subscription plans, or any other attribute from related tables. At this point, you either need: a) to go back to querying the raw, expensive event data to answer this question, or b) add additional dimensionality to the base table (e.g. first one row per day and referral source, then someone asks for a filter on subscription plan so you add that column and increase the granularity, and so on).
The way I like to set this up combines modeling this in dbt and Omni together:
Using dbt, create a table that returns a single row per
user_idand date on which that user had activity. This substantially downsizes the data from raw event logs, and you still maintain whether each individual was active on any given day.Use Omni to explore the number of active users at a daily/weekly/monthly grain (and many other timeframes, calculated at query time). Since you retained user-level information, you can add joins out to our users, subscriptions, and any other relevant tables.
Omni writes SQL on behalf of the user to allow filtering, pivoting, drilling, etc. across all available columns to write optimized SQL that only references the tables and columns it needs for the query at hand.
The benefit of this hybrid approach is that you can reap the performance and cost benefits of pre-aggregating the data. Additionally, non-technical folks get flexibility to experiment with granularity, filters, dimensionality, and drill-downs because the final aggregation happens at query time.
Navigating the gray area #
In some cases, either Omni or dbt will do the job. For example, it probably doesn’t matter all that much whether you persist users.full_name as the concatenation of first and last name into the database, or it runs at query time. In the truly gray areas, look to the skills and preferences of your team. A “data team” can be a single person wearing many hats, a couple of SQL experts, or a collection of data engineers, analysts, and data scientists. Best practices for your organization will depend on maximizing the skills of your team.
Even though I like to think of myself as pretty stellar at SQL, I find Omni to be the easiest place to iterate on analytical work. I often don’t know what I need modeled until I’ve started trying to build a dashboard or report, so I start by playing with the data and testing things in Omni, then selectively promote the things that I want pushed down through dbt (you can learn how to do this in our dbt integration post). Being an early-stage company without a dedicated data team, the most important thing is moving fast and being flexible, while contributing to a centralized data model over time.
Wrapping it up #
Defining a data model is essential to building accuracy, reusability, and trust in your data processes, but I also don’t believe this should force you to compromise on the speed of ad hoc exploration. Data governance and self-service don’t need to be at odds as they have been for decades; the key is finding the right tools and workflow for your use cases and team and having the flexibility to adjust over time. With Omni, we’re building this balance into the analytics workflow so you don’t need to compromise, whether you’re using just Omni or pairing us with other tools.
If you’d like to explore this workflow in Omni, we’d love to show you.